
Ankunft der NVIDIA DGX Spark
Kurzer Disclaimer vorweg: Alle Informationen rund um das Gerät basieren auf dem Stand von November und Dezember 2025. Die Entwicklung im Bereich KI ist sehr schnelllebig und kann sich innerhalb weniger Monate grundlegend verändern.
Voller Vorfreude fand das Unboxing statt, das wir ebenfalls in einem Video für euch festgehalten haben.
Erste Schritte mit der NVIDIA DGX Spark
Nachdem wir das Gerät angeschlossen und gebootet hatten, kam die erste Überraschung: Wie vergibt man eine feste IP-Adresse? Da wir dies kurzfristig mit einfachen Mitteln nicht umsetzen konnten, haben wir auf unserem DHCP-Server die MAC-Adresse an eine feste IP gebunden.
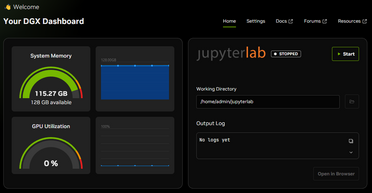
Dann folgte die nächste Überraschung: SSH-Zugriff war vorhanden, aber wie gelangt man auf das WebUI? Nach dem Durchforsten der Anleitung fanden wir heraus, dass dafür ein Client-Programm von NVIDIA notwendig ist: NVIDIA Sync. Dieses baut eine Brücke über localhost zum WebUI auf. So konnten wir uns schließlich über http://localhost:11000 mit dem WebUI verbinden.
Das WebUI präsentierte ein kleines Dashboard mit RAM- und GPU-Auslastung sowie einigen wenigen Links. Zudem gab es die Information, dass Updates zur Verfügung stünden. Also führten wir zunächst die Updates durch. Allerdings verschwand dieser Hinweis nach der Installation nicht, sondern zeigte weiterhin an, dass Updates verfügbar seien. Nachdem wir diesen Vorgang dreimal wiederholt hatten, ließen wir es dabei bewenden.
Auf Betriebssystem-Ebene gab es nämlich nach dem Ausführen von apt update und apt upgrade keine neuen Updates mehr.
Herausforderungen
In diesem Dashboard gab es einen Link zur Dokumentation, welche aus diversen Playbooks bestand, die man Schritt für Schritt durchführen konnte. Interessant für uns waren insbesondere die Tutorials, die darauf abzielten, einen OpenAI-API-kompatiblen Inference-Server bereitzustellen, um lokale KI-Modelle innerhalb von ALBERT | AI nutzen zu können.
Der erste Versuch war ein SGLang Inference Server. Leider hagelte es beim Versuch, das Playbook durchzuführen, nur so von Fehlermeldungen, sodass wir diesen Ansatz zunächst verworfen haben.
Da wir bereits in der Vergangenheit einiges an Erfahrung mit Ollama gesammelt hatten, war dies der nächste Versuch. Also installierten wir, basierend auf dem Playbook, open-webui zusammen mit Ollama, was uns ermöglichte, innerhalb einer ansprechenden Oberfläche Modelle zu laden und bereitzustellen.
Hier ergab sich wiederum die Herausforderung, den Zugriff von außen zu ermöglichen. Dafür mussten wir einiges am Startskript anpassen, um von außen eine Verbindung zum Docker-Container herstellen zu können. So, wie es im Playbook beschrieben war, hatte es bei uns nicht funktioniert.
Startskript für Open WebUI
#!/usr/bin/env bash
set -euo pipefail
NAME="open-webui"
IMAGE="ghcr.io/open-webui/open-webui:ollama"
cleanup() {
echo "Signal received; stopping ${NAME}..."
docker stop "${NAME}" >/dev/null 2>&1 || true
exit 0
}
#trap cleanup INT TERM HUP QUIT EXIT
# Ensure Docker CLI and daemon are available
if ! docker info >/dev/null 2>&1; then
echo "Error: Docker daemon not reachable." >&2
exit 1
fi
# Already running?
if [ -n "$(docker ps -q --filter "name=^${NAME}$" --filter "status=running")" ]; then
echo "Container ${NAME} is already running."
else
# Exists but stopped? Start it.
if [ -n "$(docker ps -aq --filter "name=^${NAME}$")" ]; then
echo "Starting existing container ${NAME}..."
docker start "${NAME}" >/dev/null
else
# Not present: create and start it.
echo "Creating and starting ${NAME}..."
docker run -d \
-p 12000:8080 \
-p 11434:11434 \
-e OLLAMA_HOST=0.0.0.0 \
--gpus=all \
-v open-webui:/app/backend/data \
-v open-webui-ollama:/root/.ollama \
--name "${NAME}" "${IMAGE}" >/dev/null
fi
fiNachdem nun endlich open-webui + Ollama lief, haben wir die ersten Modelle geladen, was auch reibungslos funktionierte. Die Modelle konnten zudem problemlos über die OpenAI-kompatible API in ALBERT | AI genutzt werden.
Jetzt kommt jedoch ein großes ABER: Die von Ollama bereitgestellten Modelle sind in der Regel so konfiguriert, dass sie lediglich ein Kontextfenster von 2048 Tokens bieten. Die Begründung dafür ist vermutlich, dass sie dadurch deutlich weniger RAM benötigen. Ein Kontextfenster von nur 2048 Tokens führt jedoch dazu, dass das Modell bei bereits geringem Input vergisst, was am Anfang stand. So hatten wir beispielsweise ein Angebot mit 50 Seiten in das Modell geladen und es gebeten, die Angebotszeilen zusammenzufassen. Die Antwort darauf lautete jedoch: Es sind keine Angebotszeilen vorhanden.
Aus vergangener Erfahrung mit Ollama wussten wir, wie wir das Modell modifizieren müssen, um ein größeres Kontextfenster zu ermöglichen. Dazu wird das Model-File via Ollama exportiert, am Ende um num_ctx [gewünschte Kontextgröße] ergänzt und daraus ein neues Modell erstellt, das anschließend wieder in Ollama zur Verfügung steht.
Das funktionierte zwar grundsätzlich, führte jedoch dazu, dass die Verarbeitung des zuvor genannten 50-seitigen Angebots mehrere Minuten dauerte, bis das KI-Modell überhaupt anfing zu antworten. Und das bei jeder neuen Anfrage erneut, was die Nutzung letztlich unbrauchbar machte.
Also haben wir uns nach alternativen Möglichkeiten umgesehen, ein Modell zu betreiben.
Dabei stießen wir auf ein weiteres Playbook für den Betrieb über vLLM.
Leider funktionierte dieses zunächst überhaupt nicht. Nach einigem Hin und Her fanden wir heraus, dass es für den Betrieb bereits ein neueres vLLM-Docker-Image von NVIDIA gab als das im Playbook angegebene (Hinweis: Das Playbook wurde inzwischen aktualisiert). Nachdem diese Hürde genommen war, konnten wir das erste Modell erfolgreich laden und testen. Und siehe da: Dank der vollständigen Nutzung des verfügbaren Kontextfensters des Modells konnte die vorherige Frage nach den Angebotszeilen schnell und zuverlässig beantwortet werden.
Wir testeten daraufhin diverse Modelle aus:
- gpt-oss-120b
- Qwen3-30B VL
- Qwen2.5-14B
- Deepseek
- Ministral 3 (leider nicht erfolgreich)
Schön zu sehen ist, dass selbst das 120b Modell von OpenAI (gpt-oss) auf der NVIDIA DGX Spark performant lief.
Betrieb von gpt-oss-120b mit vllm
Anbei die Skripte, mit denen wir innerhalb einer Docker-Umgebung gpt-oss zum Laufen gebracht haben:
Und um vLLM mit gpt-oss innerhalb des Containers zu starten, erfolgt dies mit folgenden Befehlen.
Zuerst wurde das passende Docker-Image gebaut:
git clone https://github.com/eugr/spark-vllm-docker.git
cd spark-vllm-docker
./build-and-copy.sh --use-wheelsDann wurde ein Container erstellt:
docker run -it --name vllm-gpt-oss --gpus all -p 8000:8000 vllm-node bashInnerhalb des Containers wurden einmalig die tiktoken-encodings geladen, die für den Betrieb von gpt-oss notwendig sind:
mkdir -p ~/tiktoken_encodings
wget -O ~/tiktoken_encodings/o200k_base.tiktoken "https://openaipublic.blob.core.windows.net/encodings/o200k_base.tiktoken"
wget -O ~/tiktoken_encodings/cl100k_base.tiktoken "https://openaipublic.blob.core.windows.net/encodings/cl100k_base.tiktoken"Der Container läuft bereits nach der Erstellung. Um ihn später erneut zu starten, geht man wie folgt vor:
docker start -i vllm-gpt-ossUnd um vLLM mit gpt-oss innerhalb des Containers zu starten, erfolgt dies mit folgendem Befehl:
# im Container
export TIKTOKEN_ENCODINGS_BASE=/root/tiktoken_encodings
vllm serve "openai/gpt-oss-120b" --gpu-memory-utilization 0.9 --max-model-len 131072 --enable-auto-tool-choice --tool-call-parser openaiNatürlich ist dieses Vorgehen vollständig manuell und dient lediglich der Verdeutlichung der einzelnen Befehle. In der Praxis würde man einen Container erstellen, der die Tiktokens lädt und vLLM direkt beim Start automatisch mit ausführt.
Hinweis: Der erste Start dauert sehr lange, da das Modell zunächst heruntergeladen werden muss. Ist das Modell bereits vorhanden, dauert es dennoch etwa fünf Minuten, bis das Modell vollständig geladen und initialisiert ist.
Erfahrungen und Best Practice
Die Nutzung lokaler KI im produktiven Einsatz ist derzeit noch eine Herausforderung und setzt voraus, dass man sich tiefgehend in die Materie einarbeitet. An dieser Stelle merkt man deutlich, dass man sich ganz vorne im Markt bewegt und sich im Monatszyklus relevante Dinge ändern. So wollten wir beispielsweise direkt die neuen Nemotron-3-Modelle (NVIDIA-Modelle) ausprobieren, was aufgrund ihres sehr jungen Entwicklungsstands jedoch noch nicht funktionierte. Entweder ist man bereit, sich vLLM selbst zu kompilieren, oder man wartet, bis NVIDIA ein entsprechendes neues vLLM-Docker-Image bereitstellt. Insgesamt fühlt sich das Arbeiten hier sehr nah an der Grenze des technisch Machbaren (Bleeding Edge) an und wirkt an vielen Stellen noch nicht vollständig ausgereift.
Die beste Betriebserfahrung haben wir mit vLLM gemacht. Ollama war, wie oben beschrieben, für unseren Anwendungsfall nicht brauchbar. Es ist jedoch durchaus denkbar, dass sich mit gezielten Parametern und entsprechendem Tuning bessere Ergebnisse erzielen lassen.
Zusammenfassend kann gesagt werden, dass die NVIDIA DGX Spark ein durchaus beeindruckendes Stück Technik ist. Wir hatten in der Vergangenheit bereits die Gelegenheit, lokale KI auf deutlich teurerer Hardware zu betreiben. Diese war jedoch einerseits weniger performant und bot andererseits deutlich weniger VRAM, sodass nur sehr kleine Modelle eingesetzt werden konnten. Umso erstaunter waren wir, auf einer so kompakten Box ein gpt-oss-120b-Modell derart schnell laufen zu sehen.
Abschließend ist noch zu erwähnen, dass es möglich ist, zwei NVIDIA DGX Spark miteinander zu verbinden, um noch größere Modelle betreiben zu können. Hierzu konnten wir jedoch bislang keine eigenen Erfahrungen sammeln.
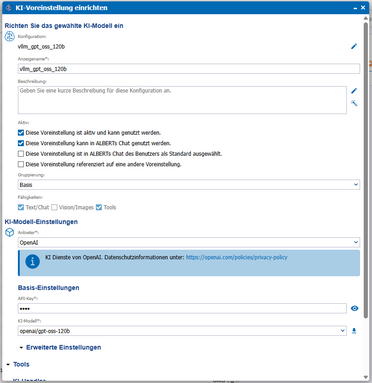
Die Nutzung innerhalb von ALBERT | AI
Zur Nutzung lokaler KI innerhalb von agorum core’s ALBERT | AI ist lediglich die Bereitstellung des KI-Modells über eine OpenAI-kompatible API erforderlich, wie sie von den meisten Inference-Programmen (z. B. Ollama, vLLM, …) bereitgestellt wird.
Innerhalb von ALBERT | AI muss lediglich eine entsprechende KI-Voreinstellung eingerichtet werden, bei der die URL auf den jeweiligen lokalen Server verweist.
Anschließend kann direkt mit der Nutzung lokaler KI gestartet werden.
Einsatz lokaler KIs: Wann macht es Sinn?
Wir werden häufig gefragt, ob man XY mit lokaler KI umsetzen kann, ob dies oder das möglich ist usw.
An dieser Stelle möchten wir daher ein wenig darüber berichten, welche Erfahrungen wir in diesem Bereich gemacht haben und wie man mit lokal betriebenen KI-Modellen umgehen sollte, um sie sinnvoll einzusetzen.
Vorab: Natürlich darf man nicht erwarten, dass eine KI, die auf Hardware betrieben wird, die um den Faktor 1.000 günstiger ist, die gleiche Leistung erbringt wie die großen Modelle von Anthropic, Google, OpenAI oder anderen Anbietern.
Der große Unterschied zwischen großen Modellen im Vergleich zu den kleineren lokal betreibbaren Modellen zeigt sich besonders stark bei der Nutzung agentischer KI, bei der das KI-Modell dynamisch auf seine Umgebung reagiert und entsprechende Strategien nutzt, um ein Ziel zu erreichen.
Bei großen Modellen reicht es in der Regel aus, einen relativ einfachen Prompt zu definieren, der das grundsätzliche Verhalten beschreibt, und dem KI-Modell Tools zur Verfügung zu stellen, über die es weitere Informationen abrufen kann. Das Modell nutzt dann viele Informationen aus der Umgebung, um selbstständig herauszufinden, wie es das gewünschte Ziel bestmöglich erreicht. Zudem verfügen große Modelle in der Regel über deutlich größere Kontextfenster, was die Verarbeitung umfangreicher Datenmengen ermöglicht. Außerdem sind sie meist in der Lage, nicht nur Text, sondern auch Bilder zu verstehen.
Bei kleineren Modellen hingegen sollten die Informationen, die das Modell zur Durchführung einer Aufgabe benötigt, bereits vorhanden oder sehr leicht abrufbar sein. Es muss deutlich klarer definiert werden, wie das Modell vorgehen soll, um sein Ziel zu erreichen. Zudem muss wesentlich strikter mit dem Kontextfenster umgegangen werden. Erhält das Modell zu viele Informationen, bricht es entweder ab oder vergisst, was zu Beginn relevant war. Darüber hinaus unterstützen nur sehr wenige offene Modelle die Verarbeitung von Bildern.
Zusätzlich zeigen sich erhebliche Unterschiede je nach eingesetztem Modell. Das eine Modell ist besonders gut im Schreiben, ein anderes im Erkennen von Bildern und ein weiteres wiederum im zuverlässigen Aufruf von Tools für agentische KI. Dies muss im produktiven Betrieb unbedingt berücksichtigt werden. Möchte man tatsächlich für jeden Anwendungsfall das jeweils beste Modell einsetzen, ist auch entsprechende Hardware erforderlich, um mehrere Modelle parallel betreiben zu können.
In all unseren Tests hat bisher das Modell gpt-oss-120b den besten Gesamteindruck hinterlassen. Es ist schnell, liefert gute Textergebnisse und beherrscht Tool-Aufrufe zuverlässig, was insbesondere für agentische KI entscheidend ist. Leider unterstützt dieses Modell keine Bildverarbeitung. Im Vergleich zu den meisten anderen Open-Weight-Modelle in unseren Tests war es jedoch das einzige Modell, das den Großteil unserer Tests problemlos absolvieren konnte.
Was funktioniert
- Erstellen von Texten
- Durchführen agentischer KI, Aufruf von Tools, sofern die Vorgehensweise nicht allzu komplex ist
- Zusammenfassen von mittelgroßen Dokumenten
- Vergleichen von mittelgroßen Dokumenten
- Extrahieren von Daten aus mittelgroßen Dokumenten (zum Beispiel aus Rechnungen all die Rechnungsinformationen)
- uvm...
Was funktioniert nicht
- Verarbeitung von sehr großen Dateien (wenn das Kontextfenster von 128.000 Tokens überschritten wird)
- Durchführung von komplexer agentischer KI, wenn die KI via Tools sehr viele Informationen sammeln und verarbeiten muss und dabei eigenständig Strategien entwickeln muss, wie das Ziel bestmöglich zu erreichen ist.
- Bilderkennung/OCR durch das KI Modell.
Strategien zum Einsatz lokaler KI
Im Rahmen unserer Tests haben wir verschiedene Strategien genutzt, um lokale KI möglichst einfach und sinnvoll einzusetzen.
In der Regel gingen wir dabei wie folgt vor: Wir erstellten die Prompts und Konfigurationen zunächst in Zusammenarbeit mit einem leistungsstarken Modell, wie beispielsweise Anthropic Claude Opus 4.5. Nachdem alles zuverlässig funktionierte, baten wir Claude, einen neuen Prompt zu formulieren, der glasklar beschreibt, wie das Modell vorgehen soll, um das gewünschte Ziel zu erreichen – unter dem Hinweis, dass es sich um ein leistungsschwächeres Modell handelt und daher besonders klare und strukturierte Anweisungen benötigt. Auf diese Weise entstand ein Kontext-Prompt, den wir anschließend mit dem lokalen Modell testeten und so lange feinjustierten, bis das gewünschte Verhalten stabil und reproduzierbar funktionierte.
Darüber hinaus hat es sich bewährt, die benötigten Ergebnisse nicht in einem einzigen Schritt erzeugen zu lassen, sondern den Prozess in mehrere klar getrennte Schritte aufzuteilen. Ein Beispiel hierfür sind die Dokumentenklassifizierung, Metadatenermittlung und Ablage:
Anstatt einen einzelnen Prompt zu schreiben, der ein Dokument klassifiziert (z. B. Rechnung, Bestellung, Angebot, …), die passenden Metadaten ausliest und anschließend noch über ein Tool die korrekte Ablage auswählt, teilen wir den Prozess in mehrere separate Aufrufe auf:
- Aufruf 1: Dokument klassifizieren (Angebot, Rechnung, Bestellung, usw...)
- Aufruf 2: Passend zur jeweiligen Klasse, die dazugehörigen Metadaten extrahieren und als JSON liefern
- Aufruf 3: Passend zu den zuvor ermittelten Daten die Ablage wählen
Die einzelnen Teil-Prompts sind dabei jeweils spezialisiert auf den entsprechenden Dokumententyp. Das ist zwar mit deutlich mehr Aufwand verbunden, führt jedoch zu wesentlich zuverlässigeren Ergebnissen. Wie bereits erwähnt, kann man hierbei wiederum ein leistungsstarkes Modell einsetzen, um die Prompts für die einzelnen Schritte und Kategorien automatisiert erzeugen zu lassen.
Spezielle Herausforderungen beim Betrieb von gpt-oss-120b
Im Rahmen unserer Tests mit der NVIDIA DGX Spark hatten wir einige Mühen, die Modelle so zum Laufen zu bringen, dass sie wirklich reibungslos funktionierten.
Als wir dem NVIDIA-Playbook folgten, um gpt-oss-120b über vLLM zu betreiben, lief das Modell zwar grundsätzlich, hinterließ jedoch insbesondere bei den Tool-Aufrufen keinen guten Eindruck. Häufig verhielt sich das Modell so, dass es ankündigte, einen Tool-Aufruf auszuführen, der entsprechende Tool-Call jedoch nicht tatsächlich gesendet wurde.
Nach langem Forschen gelang es uns schließlich, gpt-oss-120b zuverlässig und stabil zum Laufen zu bringen.
Dazu erstellten wir ein Docker-Image, anhand eines Github-Projektes, das ein VLLM-Image speziell für die DGX Spark erzeugt: https://github.com/eugr/spark-vllm-docker
Mit diesem Image konnten wir gpt-oss-120b schließlich erfolgreich mit vollem Kontextfenster und zuverlässigem Tool-Calling starten:
vllm serve "openai/gpt-oss-120b" --gpu-memory-utilization 0.9 --max-model-len 131072 --enable-auto-tool-choice --tool-call-parser openaiTipps zur Hardware-Auswahl für lokale KI
An dieser Stelle geben wir ein paar Tipps zur Hardware-Auswahl, basierend auf unseren Erfahrungen.
Fragen vorab:
- Welches Modell will ich betreiben?
- Wie viel Kontextgröße wird benötigt?
- Wie schnell soll das Modell laufen?
- Wie viele Benutzer arbeiten gleichzeitig mit der KI?
- Wie viele automatisierte Agenten arbeiten mit der KI?
Unsere Antworten dazu:
- Modell: Aktuell ist gpt-oss-120b ein sehr gutes Modell, was für viele Einsatzbereiche ausreichend ist. Soll es jedoch deutlich leistungsstärker werden, beispielsweise ein GLM 4.7 mit 358 Parametern, ist dafür eine völlig andere Hardware-Klasse erforderlich.
- Kontextgröße: so viel, wie möglich. Bei den meisten Open-Weight-Modellen liegt die maximale Kontextgröße bei bis zu 128.000 Tokens, was für die meisten Anwendungsfälle ausreicht. Große Kontextfenster benötigen jedoch auch entsprechend mehr GPU-RAM, was bei der Hardware-Auswahl berücksichtigt werden muss.
- Geschwindigkeit: Im Rahmen unserer Tests mit der NVIDIA DGX Spark und gpt-oss-120b erreichten wir einen Output von etwa 40 Tokens pro Sekunde, was sich subjektiv angenehm schnell anfühlte. Hier kommt es stark auf den Einsatzzweck an: Wird es im Rahmen eines Chats genutzt und der Benutzer wartet auf eine Antwort, dann kann es gar nicht schnell genug sein. Läuft die KI jedoch eher im Hintergrund, dann ist es in der Regel auch in Ordnung, wenn etwas ein paar Sekunden länger dauert.
- Parallele Nutzung: Je mehr Benutzer oder Agenten gleichzeitig auf die KI zugreifen, desto langsamer werden die Antwortzeiten. Ist eine hohe Geschwindigkeit für Endnutzer entscheidend, muss entsprechend ausreichend Hardware eingeplant werden. In der Praxis bedeutet dies häufig den parallelen Betrieb mehrerer Server, zwischen denen die Anfragen verteilt werden.
FAQ Häufig gestellte Fragen zu lokaler KI mit NVIDIA DGX Spark
-
Wie integriere ich die NVIDIA DGX Spark in ALBERT | AI?
Die Integration in ALBERT | AI ist unkompliziert, da das System offene Standards nutzt. Sobald auf der DGX Spark ein Inference-Server (wie vLLM) läuft, der eine OpenAI-kompatible API bereitstellt, muss lediglich die URL dieses Servers in den KI-Voreinstellungen von ALBERT | AI hinterlegt werden. Danach ist die lokale KI sofort einsatzbereit.
-
Warum empfiehlt der Test vLLM statt Ollama für den produktiven Einsatz?
In unserem Praxistest zeigte sich, dass Ollama standardmäßig das Kontextfenster auf 2048 Tokens begrenzt. Dies führte dazu, dass die KI bei längeren Dokumenten (z. B. 50-seitige Angebote) Inhalte „vergaß“. Zwar lässt sich das Fenster manuell vergrößern, dies führte jedoch zu massiven Performance-Einbußen. vLLM hingegen lief mit dem Modell gpt-oss-120b stabil, schnell und unter Nutzung des vollen Kontextfensters.
-
Welche KI-Modelle laufen am besten auf der NVIDIA DGX Spark?
Unsere Tests haben ergeben, dass das Modell gpt-oss-120b das beste Verhältnis aus Leistung und Geschwindigkeit bietet (ca. 40 Tokens/Sekunde). Es eignet sich hervorragend für Textgenerierung, Zusammenfassungen und Tool-Calling. Kleinere Modelle waren oft weniger präzise, während sehr große Modelle (wie GLM 4.7) mehr Hardware-Ressourcen benötigen, als eine einzelne DGX Spark bietet.
-
Wo liegen die Grenzen lokaler KI im Vergleich zur Cloud?
Lokale KI ist ideal für Datenschutz-kritische Aufgaben, Zusammenfassungen und klar definierte Prozesse. Grenzen gibt es bei extrem komplexer „agentischer KI“, die eigenständig Strategien entwickeln muss, sowie bei sehr großen Kontextmengen (über 128.000 Tokens). Zudem unterstützen viele leistungsfähige Text-Modelle (wie gpt-oss) derzeit noch keine Bilderkennung.
-
Welche Hardware-Voraussetzungen gelten für lokale KI im Unternehmen?
Die Hardware-Wahl hängt vom Anwendungsfall ab. Für den Betrieb von Modellen der 120B-Klasse mit akzeptabler Geschwindigkeit (für Chats oder Ad-hoc-Anfragen) ist Hardware wie die NVIDIA DGX Spark gut geeignet. Wichtig ist vor allem ausreichend VRAM für das gewünschte Kontextfenster. Bei vielen gleichzeitigen Nutzern oder Agenten müssen ggf. mehrere Server parallel betrieben werden.
Ausblick
Wie eingangs erwähnt, spiegelt dieser Artikel den Stand von Ende 2025 wider. Im Open-Source- bzw. Open-Weight-Modellmarkt bewegt sich derzeit sehr viel. Entsprechend kommen kontinuierlich leistungsstärkere Modelle auf den Markt, die eine echte Konkurrenz zu den großen Modellanbietern darstellen.
So hatten wir beispielsweise die Möglichkeit, ein GLM-4.7-Modell mit 358 B Parametern zu testen. Dieses hinterließ einen sehr guten Eindruck und ist in seiner Leistungsfähigkeit mit Modellen von Anthropic oder OpenAI vergleichbar. Aufgrund seiner Größe konnten wir dieses Modell jedoch nicht lokal betreiben, da uns hierfür die entsprechende Hardware fehlte.